My Talk on FIRST-TC Amsterdam2019.
Our team operates China’s largest PDNS database. In the hundreds of billions of DNS requests per day, we can see more than 200k NOD (Newly Observed Domain), many of which are malicious websites, including but not limited to porno and gambling, malicious APP promotion, and so on.
These malicious websites deliberately use NOD to constantly change their identities to avoid blocking. At the same time, they will use various methods to evade detection, including simulating normal websites, filling irrelevant content, JS lazy loading, displaying content with pure images, etc.
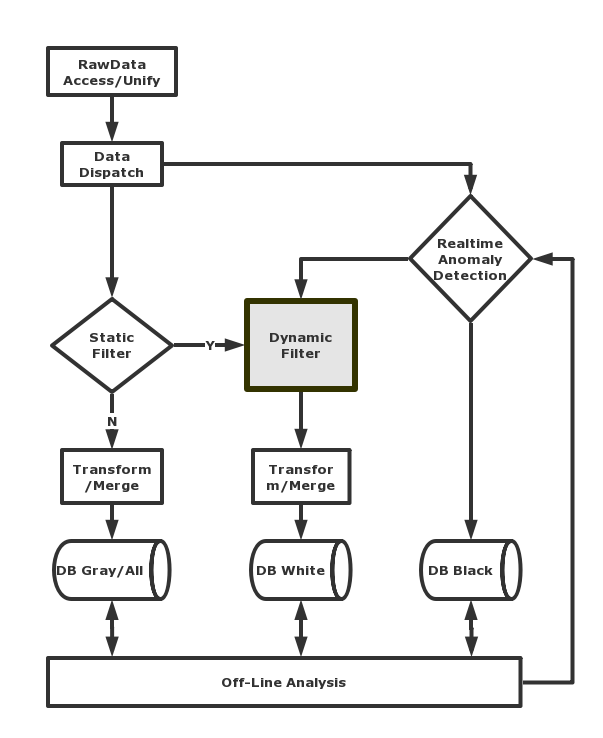
After analysis, we found that these malicious websites are endless and varied, while the resources be used by them are relatively fixed, such as the same statistical links, same images, embedded JS code segments, download resources, three-party plug-ins with ID, etc. . All of the above can be tagged as “malicious resources”, and normal websites will never load them. Based on this feature, we can use the relationship between the websites and their loading resources to detect various malicious websites in the NOD.
At the same time, there are way too many malicious resources, and they are constantly being added. It is impossible for us to manually search and operate. We have also implemented an automatic discovery process for malicious resources. The malicious websites in NOD are tagged by the old malicious resources, and the new malicious resources are automatically discovered. The whole loop process requires only a small amount of manual review, and the automatic detection of most malicious websites in the full amount of NOD can be realized.
Download: Automatic discovery of malicious websites in NOD.PDF